
Web Service
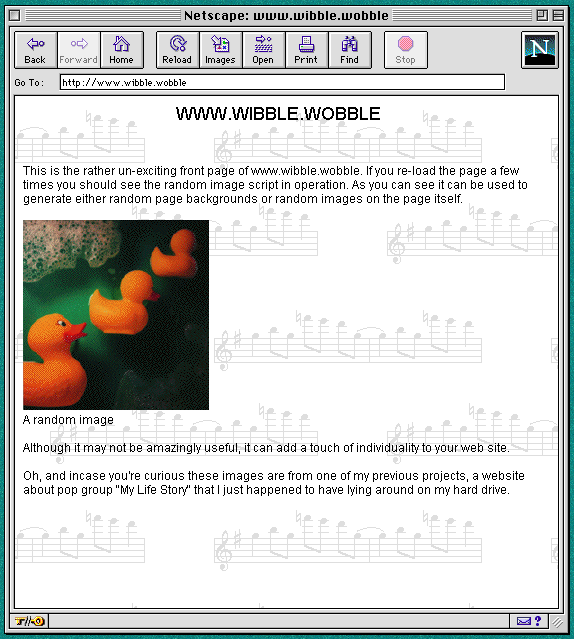
| If you enter the URL http://localhost or http://dev.amigasoc.org into a web browser running on your machine you should be presented with the AmigaSoc front page, whilst the URL http://www.wibble.wobble will present you with a Wibble test page. If you reload the Wibble home page a number of times you will notice that the background and the picture on the page change everytime. This is done using a perl cgi script, shown in listing 1. The HTML source code for the page contains references to the script instead of to an image file. Everytime you load this page Apache runs the script and acts upon the output. In this case our script returns the path to an image file, so Apache loads that image onto the web page. The script itself is quite simple. As with last months shell scripts the first line tells NetBSD which interpreter to use to run the script, which is in this case the path you`ve installed the perl binary in. The script then reads the contents of an image directory into an array called "@images" using a combination of the perl "split" and unix "ls" commands. |
|
Location:, however if we are using cgi to generate entire web pages we would use the HTTP header, Content-type:text/html\n\n.
$email_address = $in{address};
| Now that cgi-lib has done the hard work, all that is left for us to do with our perl script is generate an http header, and an appropriate html page. There are three different versions of the feedback script, feedback.pl, included on the CD. The first version simply prints the contents of the feedback form back to the user. The second version prints the data back, but also includes the AmigaSoc logo and background, whilst the third version emails the form data to the AmigaSoc webmaster and generates a confirmation html page personally addressed to the user who entered the data. |
| A final trick used by cgi is the use of environment variables to obtain certain information about the person reading the page. Usually these take the form of a personalised greeeting, however as web browsers seem to be coming more and more incompatible use of the HTTP_USER_AGENT variable is becoming more common to tell surfers to upgrade or change their browser. Table 1 shows some of the common environment variables supported by most web browsers. |
| ||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}